
De la nécessité d’une science avec conscience
 Souvenons-nous des années 80 et 90 : quelques mots étaient en capacité d’enchanter n’importe quel film, histoire ou livre d’une couleur d’avant-garde. Le nombre « 2000 », les ordinateurs personnels, « l’» internet, les autoroutes de l’information, les systèmes experts et… déjà l’intelligence artificielle (IA). A leur seule évocation, ces termes arrivaient à peupler les esprits de voitures volantes, de machines dépassant leurs concepteurs pour les anéantir, d’êtres humains hybridés avec des robots.
Souvenons-nous des années 80 et 90 : quelques mots étaient en capacité d’enchanter n’importe quel film, histoire ou livre d’une couleur d’avant-garde. Le nombre « 2000 », les ordinateurs personnels, « l’» internet, les autoroutes de l’information, les systèmes experts et… déjà l’intelligence artificielle (IA). A leur seule évocation, ces termes arrivaient à peupler les esprits de voitures volantes, de machines dépassant leurs concepteurs pour les anéantir, d’êtres humains hybridés avec des robots.
En ce qui concerne l’IA, il semble d’ailleurs que la résurgence de nouveaux espoirs réponde à des cycles trentenaires (1950, 1980 et maintenant 2010) où a succédé à l’enthousiasme des pionniers la déception des praticiens.
Qu’en dire en 2018 ?
Peut-être que l’IA a longtemps été une science d’avenir, qu’elle l’est encore et qu’elle risque de le rester si l’on écoute Yarden Katz. Ce jeune chercheur à la Harvard Medical School estime en effet que l’actuelle « révolution de l’IA » est fabriquée de toute pièce pour promouvoir en réalité un projet de gouvernance global par les nombres. Il résume en une caractéristique ce qu’il considère comme une prétendue « ère » : le « manque de conscience » (thoughtlessness) à ne réduire l’humain qu’à son seul comportement dans une société quantifiée[1].
D’autres auteurs en France ou à l’étranger nous avertissent des mêmes dangers[2]. Faut-il voir dans ces propos la résistance d’un ancien monde contre la transformation en cours, une critique politique du projet néo-libéral cachée sous des atours technologiques ou une objectivation bienvenue dans cette nouvelle période d’enthousiasme (d’exaltation ?).
Tentons de revenir sur quelques constats factuels pour tenter de définir ce qui se cache derrière la « hype de l’IA » [3] et évoquer le risque de total discrédit si les promesses à nouveau formulées ne parviennent pas à être remplies. Au final, les approches transdisciplinaires souvent réclamées ne devraient-elles pas se concrétiser au travers d’une nouvelle formalisation des savoirs dotée d’une solide conscience ?
1/ L’IA : de quoi parle-t-on exactement ?
La croissance exponentielle de l’efficacité du traitement informatique des données est à distinguer totalement des progrès considérables restant à réaliser par la recherche fondamentale pour modéliser une intelligence aussi agile que l’intelligence humaine. Certains avaient cru pouvoir la réduire à « 10 millions de règles[4] » : des chercheurs comme Yann LeCun affirment aujourd’hui que l’IA se heurte en réalité à une bonne représentation du monde, qui est une question « fondamentale scientifique et mathématique, pas une question de technologie[5] ». Une dichotomie est donc parfois réalisée entre l’« IA forte » de science-fiction (généraliste, auto-apprenante et adaptable de manière autonome à des contextes tout à fait différents), et les IA « faibles » ou « modérées » actuelles, ultra-spécialisées et non-adaptables de manière totalement autonome à des changements complets de paradigme[6]. Cette distinction ne clarifie toutefois pas ce que l’on entend par « intelligence » et alimente nombre de malentendus et de fantasmes, entretenus et véhiculés par les médias (qui peinent à décrypter les discours commerciaux et à vulgariser des concepts complexes).
Commençons par rappeler que les mécanismes actuellement mis en œuvre sous le terme « IA » sont pluriels et ne sont pas réellement nouveaux[7]. Ce qui l’est, c’est leur synergie et leur efficacité de traitement, rendues possibles par la performance des processeurs actuels et la baisse du coût de stockage de quantité considérable de données.
Pour être plus précis, cet assemblage de sciences et techniques (matérialisé par différentes classes d’algorithmes, en annexe) a contourné de manière extrêmement astucieuse les limites des anciens systèmes experts, qui exigeaient de programmer a priori des règles logiques de traitement de données pour imiter un raisonnement. Les approches actuelles sont inductives : l’idée est de réunir un nombre suffisant de données d’entrée et de résultats attendus en sortie afin de rechercher de manière (plus ou moins) automatisée les règles pouvant les lier. Cette recherche automatisée est ce que l’on qualifie d’apprentissage dans les algorithmes d’ « apprentissage machine » (machine learning) et se trouve formalisée dans un modèle décrivant mathématiquement les relations découvertes.
Les approches actuelles sont inductives : l’idée est de réunir un nombre suffisant de données d’entrée et de résultats attendus en sortie afin de rechercher de manière (plus ou moins) automatisée les règles pouvant les lier. Cette recherche automatisée est ce que l’on qualifie d’apprentissage dans les algorithmes d’ « apprentissage machine » (machine learning) et se trouve formalisée dans un modèle décrivant mathématiquement les relations découvertes. 
L’objectif pour les ingénieurs n’est pas de comprendre les règles ou modèles automatiquement construits par l’ordinateur mais de s’assurer que la machine arrive à reproduire de mieux en mieux les résultats attendus, si nécessaire avec toujours plus de données par des phases successives d’ « apprentissage ».
2/ Les trois clés possibles de compréhension de l’IA
Tentons de reformuler les concepts esquissés précédemment :
- l’IA n’est pas un objet unique et homogène : il s’agit en réalité d’un assemblage de sciences et techniques (mathématiques, statistiques, probabilités, neurobiologie, informatique) en capacité de traiter des données pour concevoir des tâches très complexes de traitement informatique ;
- le moteur de l’IA ne produit pas de l’intelligence en soi mais fonctionne par une approche inductive : l’idée est d’associer de manière plus ou moins automatisée un ensemble d’observations (entrées) à un ensemble de résultats possibles (sorties) à l’aide de diverses propriétés pré-configurées ;
- la fiabilité du modèle (ou fonction) construit sur cette base dépend fortement de la qualité des données utilisées et du choix de la technique d’apprentissage automatisée (machine learning).
Le concept d’IA est donc globalement à démystifier si l’on s’en tient à une interprétation stricte du mot « intelligence ». Nous avons affaire à des machines mathématiques, statistiques et probabilistes complexes et non des répliques (même sommaires) du cerveau humain (qui inclut des processus perceptifs, l’apprentissage, l’auto-organisation, l’adaptation). Prenons l’une de sous-classes du machine learning, les réseaux de neurones : si leur conception est bien inspirée des neurones biologiques, leur fonctionnement est en réalité fortement optimisé par des méthodes probabilistes dites bayésiennes. En d’autres termes, ces réseaux sont aussi comparables à de réels neurones que les « animatronics » de Disneyland sont similaires à des humains.
3/ Comment prévenir le risque de discrédit lorsque les promesses ne seront tenues
Le problème majeur, s’il y en avait un à qualifier, c’est la confusion entretenue entre les succès incontestables de l’IA dans des champs bien précis d’application et leur transposition dans des champs pour lesquels son utilisation apparaît comme bien plus contestable.
Lors d’une récente conférence tenue à Bologne sur la Cyberjustice, un jeune avocat italien affirmait que toutes les disciplines des sciences sociales pouvaient désormais être modélisées par l’IA[8]. La toute-puissance des méthodes inductives flottait dans l’air et à l’entendre la modélisation du monde dans son entier était à portée… Le « manque de conscience » dénoncé par Yarden Katz était pourtant bien plus présent dans la salle que la révolution annoncée puisqu’il n’y avait personne du milieu académique pour partager avec lui les conclusions déjà citées de Yann LeCun ou l’interroger sur les raisons pour lesquelles Auguste Comte avait rompu avec la « physique sociale » pour parler de « sociologie »[9]. Certaines des entreprises commercialisant des services bâtis sur l’IA paraissent souvent négliger ces acquis, peut-être par méconnaissance, peut-être aussi pour ne pas décourager leurs sponsors financiers…
Évoquons toutefois quelques aspects pour lesquels tout concepteur d’IA devrait avoir des réponses pour démontrer les mesures qu’il a pu prendre… en conscience et pour ne pas discréditer la matière.
La cohérence des données analysées devrait tout d’abord pouvoir être démontrée : l’un des défauts de l’IA, c’est le risque de concevoir des modèles avec des données d’entrée et des résultats a priori de même nature mais en réalité légèrement discordants. Parvenir à constituer des jeux de données cohérents pour faire décoller une fusée, analyser une image ou jouer au go est un objectif complexe mais réalisable (pour le go, il s’agit de pierres noires, blanches, 19 lignes sur 19, des règles de jeu claires). Les sciences sociales posent de toutes autres difficultés de collecte : il est même parfois impossible de s’assurer que les résultats mesurés empiriquement procèdent exactement des mêmes causes. En ce sens, la réduction des biais dans les données utilisées pour l’apprentissage est un prérequis indispensable : des données biaisées produiront des modèles biaisés, qui reproduiront des résultats biaisés. Ceci étant dit, réunir des données sans biais est un exercice qui est peut-être impossible. Aleš Završnik, professeur associé à la faculté de droit de Ljubljana, affirmait lors d’une conférence à l’école polytechnique fédérale de Zurich (ETH) que nous en sommes réduits en réalité à choisir entre les biais purement humains ou les biais humains transférés dans les machines[10].
Citons aussi le phénomène du data snooping ou du data dredging, qui est à l’origine de nombreuses approximations[11]. Ces termes qualifient la sélection (dans un grand nombre de données et de résultats) d’un échantillon présentant à lui seul des associations statistiquement significatives, échantillon réemployé ensuite pour confirmer cette hypothèse. Pour résumer, cela revient à tirer une série de balles dans un mur puis dessiner ensuite une cible autour pour confirmer que vous l’avez bien touché. C’est aussi ce que les mathématiciens Cristian Sorin Callude et Giuseppe Longo dénoncent comme étant « le déluge des corrélations fallacieuses dans le big data »[12]. Tout résultat statistique serait en réalité à élargir à d’autres échantillons pour être vérifié et surtout ne pas fonder à lui seul des conclusions : ils pourrait être recoupés avec d’autres sciences ou techniques pour confirmer sa plausibilité[13].
Enfin, l’effet performatif est parfaitement connu mais en général non traité : un système apprenant sur la base de résultats qu’il contribue à produire risque fort de s’autoalimenter et de n’être représentatif que de lui-même. Le problème est aujourd’hui souvent identifié mais aucune solution concrète n’est proposée.
Les travers propres à l’interprétation des résultats produits par l’IA (renforcement des discriminations sur des facteurs ethniques, économiques, sociaux) ne seront pas développés ici mais justifient une réelle évaluation transdisciplinaire (économique, sociale, sociologique, philosophique, juridique) par des comités éthiques avant de mettre en œuvre tout traitement relatif à des individus[14]. Chaque cas d’utilisation de l’IA serait donc à considérer de manière globale pour le qualifier, peut-être aussi au travers d’une science spécifique à construire ? Iyad Rahwan et Manuel Cebrian, chercheurs au MIT, invitent à bâtir une nouvelle discipline scientifique relative au comportement des machines[15]. En écho, Nicolas Nova rappelait dans sa lettre d’information Lagniappe du 13 mai 2018, que les Sciences & Technologies Studies (STS) répondent déjà à ce besoin et que l’on pourrait plutôt s’interroger sur les raisons pour lesquelles les ingénieurs, les scientifiques, les chercheurs des différents champs semblent parfois s’ignorer les uns les autres[16]. Le manque réciproque de connaissances épistémologiques est une évidente possibilité.
Les promesses renouvelées durant ces dernières années visant à bâtir une réelle IA ne seront donc vraisemblablement pas tenues. Une fois la « hype » dissipée, la déception qui y succédera risque fort de compromettre le financement de nouveaux projets de recherche ou de nouvelles réalisations alors même que des potentialités existent dans des champs bien précis[17]. Le concept d’IA est donc à objectiver et à démystifier de manière urgente non pour résister aux changements de notre monde mais de manière à ne pas compromettre l’extraordinaire potentiel de cette puissance nouvelle de calcul à cause de discours hâtifs et exaltés, aux motifs pour le moins variables.

Magistrat et maître de conférences associé à l’université de Strasbourg
Auteur des ouvrages « L’intelligence artificielle en procès » (Bruylant) et « IA générative et professionnels du droit » (LexisNexis)
Les opinions exprimées n’engagent que son auteur.
Aller plus loin ?
Les différentes classes d’algorithme constituant l’IA et l’apprentissage machine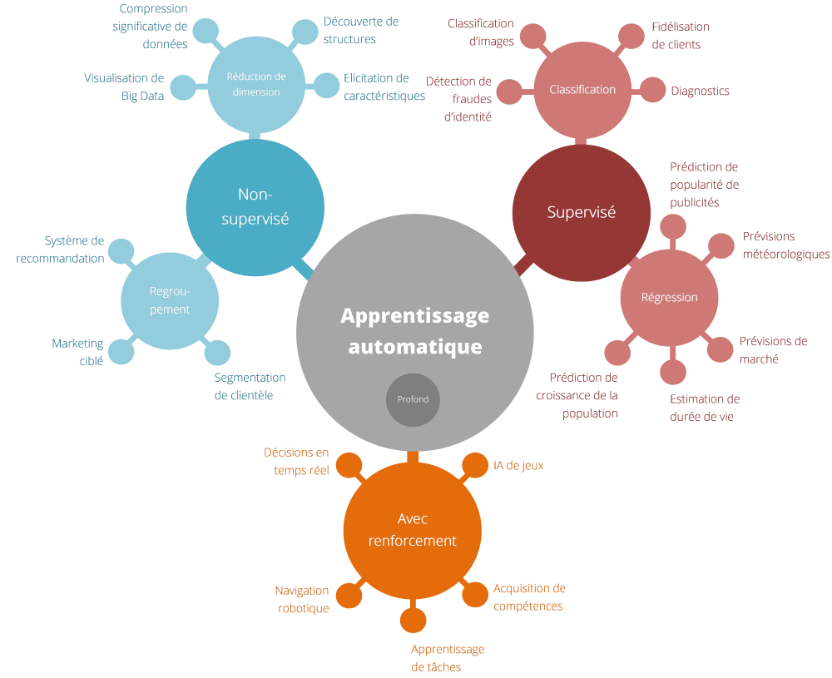
Notes
[1] Yarden Katz, Manufacturing an Artificial Intelligence Revolution, SSRN, 17 novembre 2017 – Consulté sur le site SSRN le 14 mai 2018 : https://ssrn.com/abstract=3078224 ou http://dx.doi.org/10.2139/ssrn.3078224
[2] Citons par exemple en France Dominique Cardon, Eric Sadin, Adrien Basdevant et Eric Mignard, Antoine Garapon et Jean Lassègue ; en Europe les travaux d’Aleš Završnik – Voir la rubrique Bibliographie de ce blog
[3] Emmanuel Barthe, Intelligence artificielle en droit : derrière la « hype », la réalité – Consulté sur le blog precisement.org le 10 mai 2018 : http://www.precisement.org/blog/Intelligence-artificielle-en-droit-derriere-la-hype-la-realite.html
[4] Douglas Lenat, chercheur en intelligence artificielle et directeur de la société Cycorp
[5] Yann LeCun, Qu’est-ce que l’intelligence artificielle, Collège de France – Consulté sur le site du collège de France le 16 juin 2017 : https://www.college-de-france.fr/media/yann-lecun/UPL4485925235409209505_Intelligence_Artificielle______Y._LeCun.pdf
[6] Distinction notamment réalisée par John Searle dans les années 1980, où il différencie un système qui aurait un esprit (au sens philosophique) et pourrait produire de la pensée d’un système qui ne peut qu’agir (même s’il donne l’impression de pouvoir penser)
[7] Le théorème de Thomas Bayes, étendus par Pierre-Simon Laplace, date du XVIIIème siècle ; les bases des réseaux neuronaux ont été développées dans les années 1940 par Warren McCulloch and Walter Pitts (Created a computational model for neural networks based on mathematics and algorithms called threshold logic, 1943)
[8] Atelier de travail « Vers une cyberjustice », tenu les 10 et 11 mai 2018 à Bologne (Italie) à l’initiative de l’IRSIG-CNR (Istituto di Ricerca sui Sistimi Giudiziari – Consiglio Nazionale delle Ricerche)
[9] « La réduction des faits sociaux à des formules mathématiques et à des indicateurs inquiétait déjà plusieurs philosophes, écrivains et hommes de science, qui y voyaient un risque de moralisation de la vie sociale par l’algèbre et les calculs » Adrien Basdevant, Jean-Pierre Mignard, L’empire des données, Don Quichotte, 2018, p. 40.
[10] Conférence « Justice automatisée : algorithms, big data et justice pénale » (Automated Justice: Algorithms, Big Data and Criminal Justice Systems) tenue le 20 avril 2018 à l’école polytechnique fédérale de Zurich (ETH) – Présentation accessible sur le site internet de l’université (anglais seulement) : https://www.video.ethz.ch/speakers/collegium-helveticum/digital-societies/automated_justice/84c3f617-8784-4203-b7a8-50a176811933.html
[11] Voir par exemple l’article de Regina Nuzzo, Statistical errors, Nature, vol. 506, 13 février 2014 – article consulté le 14 mai 2018 accessible par le lien suivant (anglais seulement) : http://sisne.org/Disciplinas/PosGrad/MetRedCient/Statistical%20errors%20(p-values).pdf
[12] Théorie dite de « Ramsey », citée par Cristian Sorin Calude et Giuseppe Longo dans La toile que nous voulons, p.156, collectif, Institut de Recherche et d’Innovation, FYP éditions ; théorie développée dans l’étude de Ronald L. Graham, Joel H. Spencer – Ramsey Theory, Scientific American, vol.263, n°1, juillet 1990, p112-117
[13] Regina Nuzzo, Statiscal errors, déjà cité.
[14] Par exemple le renforcement des discriminations tel qu’en témoigne le logiciel COMPAS aux Etats-Unis ou HART en Grande-Bretagne qui prétendent évaluer la risque de récidive des personnes mises en cause dans des affaires pénales
[15] Iyad Rahwan, Manuel Cebrian, Machine Behavior needs to be academic discipline, Nautilus, 29 mars 2018 – Consulté le site Nautilus le 14 mai 2018 (anglais seulement) : http://nautil.us/issue/58/self/machine-behavior-needs-to-be-an-academic-discipline
[16] Nicolas Nova est chercheur et Professeur associé à la Haute École d’art et de design à Genève, sa lettre d’information est accessible à l’adresse suivante : https://tinyletter.com/nicolasnova
[17] Voir notamment les propos de Michael I. Jordan dans Le Monde, 1er décembre 2015, où il estime notamment que « le battage médiatique autour des possibilités excitantes de l’analyse du big data est trop important. Les attentes actuelles dépassent de loin la réalité de ce que l’on peut obtenir. Le problème est que lorsque de telles attentes ne sont pas remplies tout de suite, la déception engendrée peut jeter un discrédit sur l’ensemble même du secteur. » – Consulté sur le site du Monde le 11 mai 2018 : http://www.lemonde.fr/sciences/article/2015/12/01/michael-jordan-une-approche-transversale-est-primordiale-pour-saisir-le-monde-actuel_4821327_1650684.html